史丹佛 Smallville 虛擬小鎮 Part.3 Agent行爲設計
筆記第三部分對應「Generative Agents: Interactive Simulacra of Human Behavior」中的 GENERATIVE AGENT ARCHITECTURE,這部分仔細摘要了 Agent 行為架構的三個機制,包含 Memory Stream、Reflection 和 Plan。
從下圖可以看到整個架構的核心是 Memory Stream,用來詳盡記錄 Agent 的所有經歷。
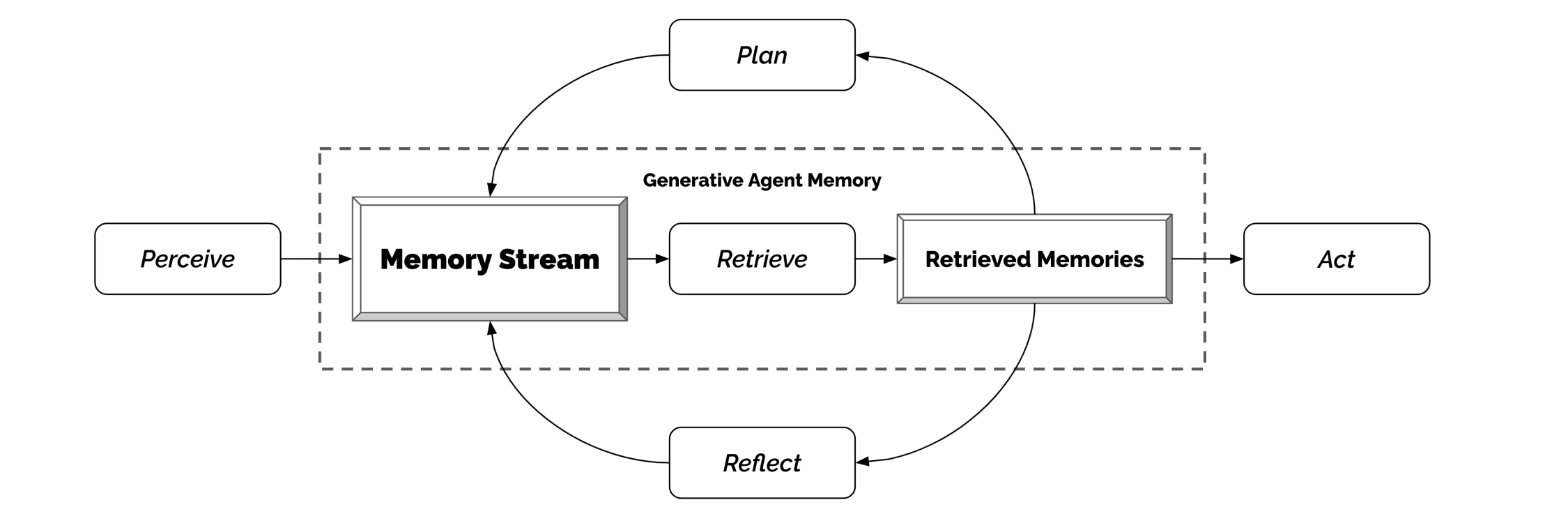 source: figure 5 from https://arxiv.org/pdf/2304.03442
source: figure 5 from https://arxiv.org/pdf/2304.03442
1. Memory and Retrieval
- Memory Stream 裡的組成單位是 Memory Object,包含:
- 自然語言描述 (Natural language description)
- 創建時間戳記 (Creation timestamp)
- 最後存取時間戳記 (Most recent access timestamp)
- 類型: 最基本的元素是「觀察(Observation)」,包含代理人自己的行為或觀察到他人的行為。
- 挑戰:所有記憶如果全部喂進去每次做計劃的 prompt,會超過 context window 限制,且也可能並不真的符合當前回答所需。
- 舉例: 詢問 Isabella 最近投入什麼事物,如果全部喂進去會得到訊息量很低的回答,但是如果把話題限縮在活動舉辦相關的,他就會提到情人節派對
- 解決方法:有 retrieval function,會根據 agent 現在的狀態來提取資訊相關的 memory stream,function 涉及三個元素:
- Recency:隨著時間指數型下降(指數衰減函數(Exponential decay function),衰減因子是 0.995。這代表隨時間流逝,記憶分數會掉得很快),越近期發生分數越高,模仿剛發生的事通常記憶鮮明的特性。
- Importance:直接問LLM取得得分數,越重要分數越高,模仿印象深刻的事。例如整理房間只有兩分,但是問暗戀的人出去有八分。
- Relevance:對記憶做query,並用 embedding vector計算 cosine similarity between the memory’s embedding vector and the query memory’s embedding vector。
- 公式:\(score = \alpha_{recency} \cdot recency + \alpha_{importance} \cdot importance + \alpha_{relevance} \cdot relevance\)
- 正規化(Normalization): 原文提到這三個分數在加總前,會先透過 Min-max scaling 縮放到 $[0, 1]$ 之間。
- 權重分配: 在目前的實作中,所有的 $\alpha$(權重)都設為 $1$。
 source: figure 6 from https://arxiv.org/pdf/2304.03442
source: figure 6 from https://arxiv.org/pdf/2304.03442
2. Reflection
- 挑戰: 原始觀察(Raw Observations)過於碎片化,導致 Agent 無法進行泛化(Generalization) 或推理深層關係。
- 舉例: Klaus 只會選見面次數最多的鄰居去喝咖啡,而不知道選志趣相投的 Maria。
- 觸發時機: 自上一次反思之後,所有新產生的記憶,其 Importance 分數的總和超過 150 時觸發(約每日 2-3 次)。
- 四步驟流程:
- 提問: 根據最近 100 條記憶,讓 LLM 提出 3 個最核心的高階問題。
- 檢索: 以這些問題為 Query,從記憶庫(含舊反思)檢索相關資訊。
- 推論: 讓 LLM 從檢索結果提取 Insights,並要求引用 記憶編號作為證據。
- 儲存: 將這些抽象的 Insight 存回記憶庫。
- 結構:Reflection Tree
- 葉節點(Leaf): 底層的觀察(看書、喝咖啡)。
- 非葉節點: 抽象思考(熱愛研究、與某人關係緊密)。越往上層越抽象。
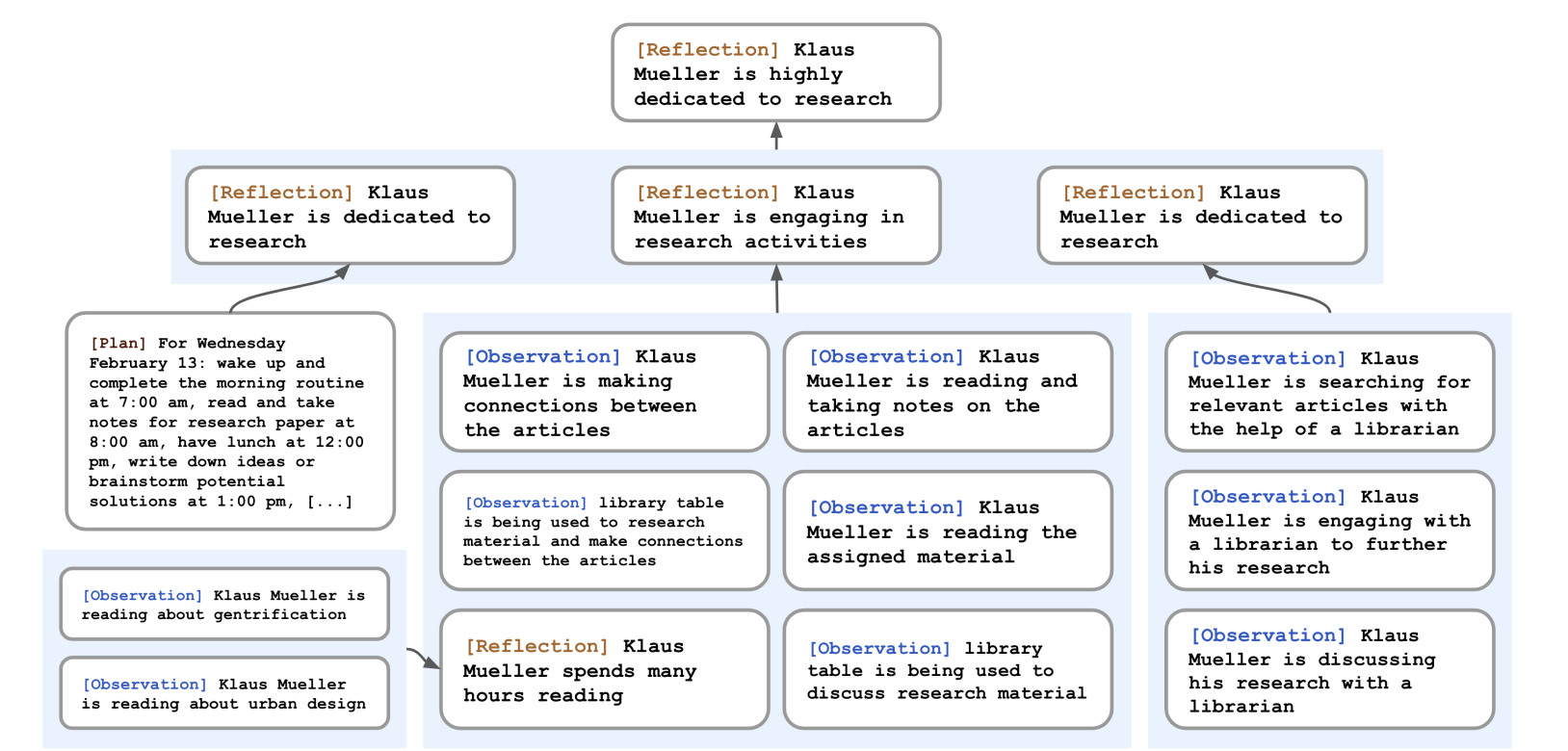 source: figure 7 from https://arxiv.org/pdf/2304.03442
source: figure 7 from https://arxiv.org/pdf/2304.03442
3.Planning and Reacting
- 挑戰:Agent 可以根據事件反映,但難以從一而終做出符合人設的行為。
- 舉例: 給LLM Klaus的背景以及現在的時間,並詢問他現在該做什麼?LLM會在十二點的時候安排他吃午餐,但是十二點半和一點又會各吃一次
-
解決方法:Plan 描述了 Agent 未來的一系列行動,並有助於保持 Agent 行為的一致性。Plan 包含 location, a starting time, and a duration。
-
與 reflection 類似,plan 也儲存在 memory stream 中,並在 retrieval 過程中被調用。這使得 Agent 在決定如何行動時,能夠同時考慮 Observation, Reflection, Plan。如有需要,Agent 可以在過程中更改其 Plan。
- Planning 的生成過程:由上而下的遞歸分解 (Top-down Recursive Decomposition) 為了避免行為太過機械化(例如連續坐 4 小時不動),系統採用遞歸方式生成細節:
- 第一步(Broad Strokes): 根據 Agent 的特質與前一天的總結,生成當天的大綱(通常分為 5-8 個區塊)。
- 第二步(Decomposition): 將大綱細分。例如將「1:00 pm - 5:00 pm 寫作」分解為每小時的具體任務。
- 第三步(Fine-grained): 進一步細分為 5-15 分鐘的微動作(例如:4:00 pm 拿個零食、4:05 pm 散個步)。
3.1 Reacting and Updating Plans
- 機制: Agent 運作於一個Action Loop中。
- 決策邏輯: 每個時間點,Agent 會感知環境,並將 Observation 存入記憶。接著詢問 LLM:「基於目前的狀態與觀察,應該繼續執行原定 Plan,還是進行 React?」
- 計畫更新: 如果決定要反應(例如:看到熟人、發現火災),系統會重新生成從當下時間點開始的 Plan。
3.2 Dialogue
Agent 之間的對話被視為一種特殊的「反應」。其生成依賴於以下資訊:Context Summary: 透過檢索針對「雙方關係」與「對方目前狀態」的記憶,生成一段背景摘要。
- 對話生成:發起者: 根據自己的特質與目標,結合背景摘要,產生第一句話。
- 接收者: 將對方的對話視為一個 Observation,檢索相關記憶,決定如何回應。
- 持續性: 對話會參考 Dialogue History 持續進行,直到其中一方決定結束。
留言
Loading comments...